Effectiveness of Autonomous AI Agents in Due Diligence
Hopfia Team
The Core of AI-Driven Due Diligence
The core challenge in AI-driven due diligence is not information retrieval, but the ability to restructure information into decision-ready insights.
Traditionally, due diligence has been conducted through checklist-based frameworks. The Due Diligence Questionnaire (DDQ) represents this approach, relying on predefined question sets to guide data collection and validation.
While effective in structuring coverage and ensuring completeness, this approach presents limitations when evaluated from an investment decision-making perspective.
Benchmark Overview
This benchmark evaluates how data room–based diligence systems perform when working with the same dataset, focusing on two key dimensions:
How effectively information is transformed into actionable findings
How those findings contribute to real decision-making
Rather than measuring output volume or response correctness at the sentence level, the benchmark focuses on how findings are constructed and whether they meaningfully contribute to investment decisions.
To ensure comparability:
Both approaches were evaluated on the same data room
The same diligence task was assigned
Input variability was minimized
The evaluation was conducted using:
Independent utility assessment of identified risks
1:1 pairing comparison across semantically similar findings
OpenAI GPT-5.4 as the evaluation model
Evaluation Metric: Information Utility
The benchmark introduces Information Utility as the primary evaluation metric.
Information Utility — The extent to which a diligence finding impacts investment decisions and contributes to decision-making
This metric evaluates:
Whether a risk is clearly defined
How that risk connects to deal-level impact
Whether the output can be directly used without additional interpretation
In this sense, Utility measures not information presence, but decision transformation capability.
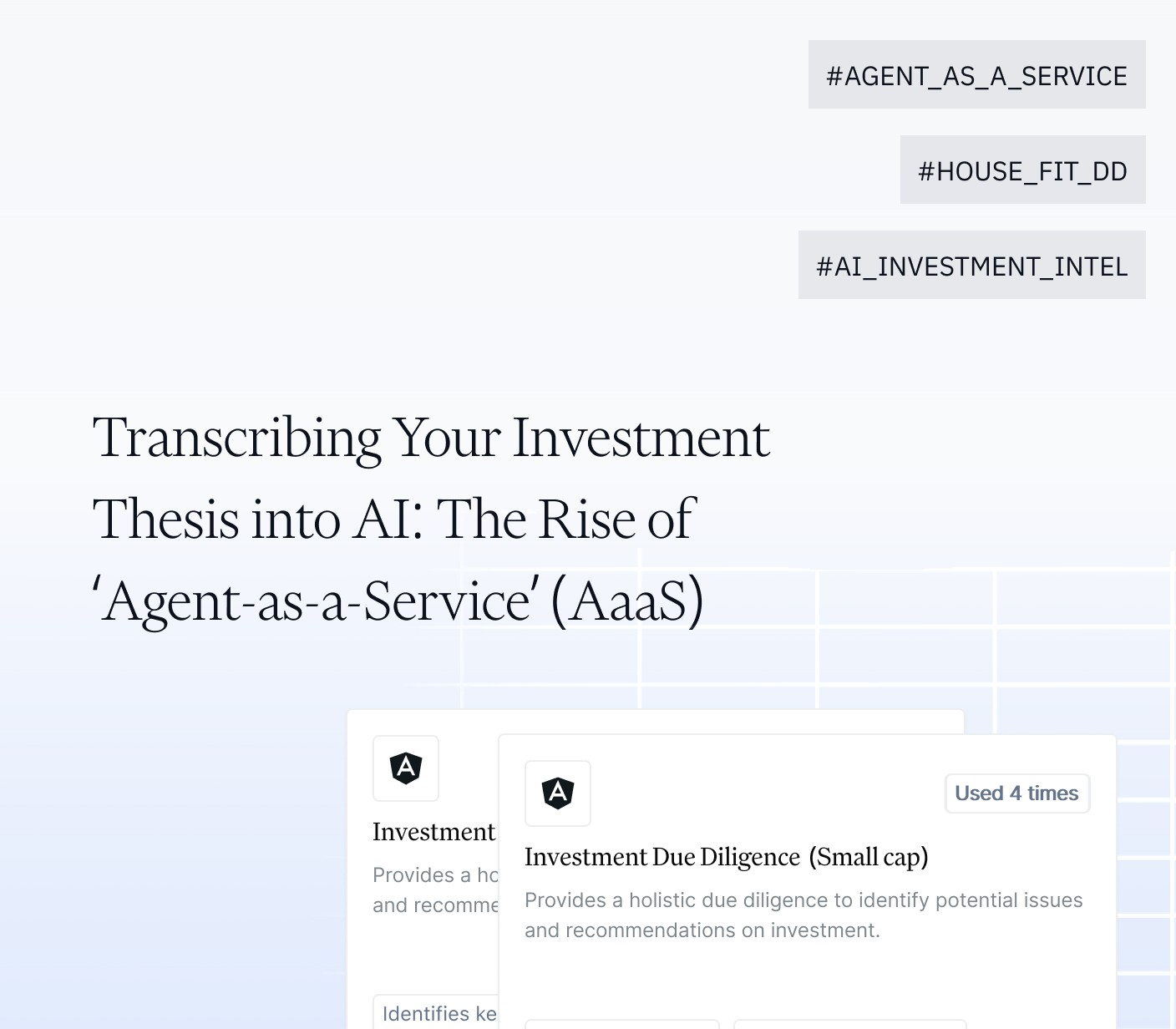
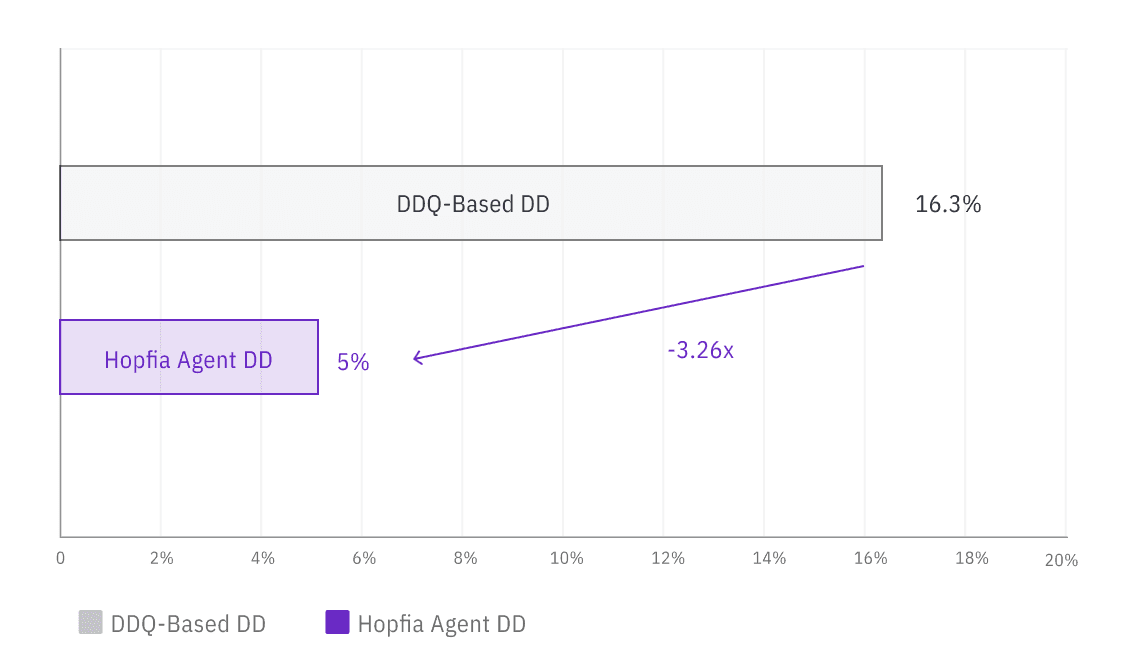
According to the benchmark results, the average Utility score for the DDQ-based approach was 0.313, whereas Hopfia’s autonomous agent–based approach achieved 0.760, representing a substantial gap of approximately 242%.
Similarly, the proportion of high-utility findings (high and above) showed a significant divergence, with 7.9% for the DDQ-based method compared to 85.3% for the autonomous agent approach—an order-of-magnitude difference exceeding 10x.
This performance gap can be attributed to a fundamental difference in how findings are constructed.
Rather than focusing on document summarization or question-level response completeness, Hopfia’s autonomous agents demonstrate a stronger capability to synthesize related pieces of information into cohesive, decision-oriented risk constructs.
In other words, instead of enumerating isolated facts, the system reorganizes them into structured insights that directly inform investment decisions.
Representative high-utility findings illustrate this pattern.
For example, findings that integrated:
delays in production facility expansion
uncertainty in commercialization timelines
capital expenditure burden
and the need for additional financing
were synthesized into a single insight highlighting liquidity risk exposure, which directly informs downside risk in the transaction.
Similarly, supply chain–related findings that linked:
the absence of long-term supply agreements or confirmed outsourcing partners
with potential failure in cost-reduction assumptions
risk of launch delays
and the need for additional capital investment
were evaluated highly, as they articulated a multi-factor operational risk with direct implications for execution and financial performance.
In addition, to assess the risk of over-confidence and potential hallucination, a Depth-Ablation diagnostic was conducted.
Each finding was evaluated under two conditions:
once with full supporting evidence included
and once with the supporting evidence partially removed
This procedure was designed to examine the extent to which the perceived utility of a finding is grounded in underlying evidence, rather than driven by the coherence or persuasiveness of the narrative alone.
The results show a clear difference between the two approaches.
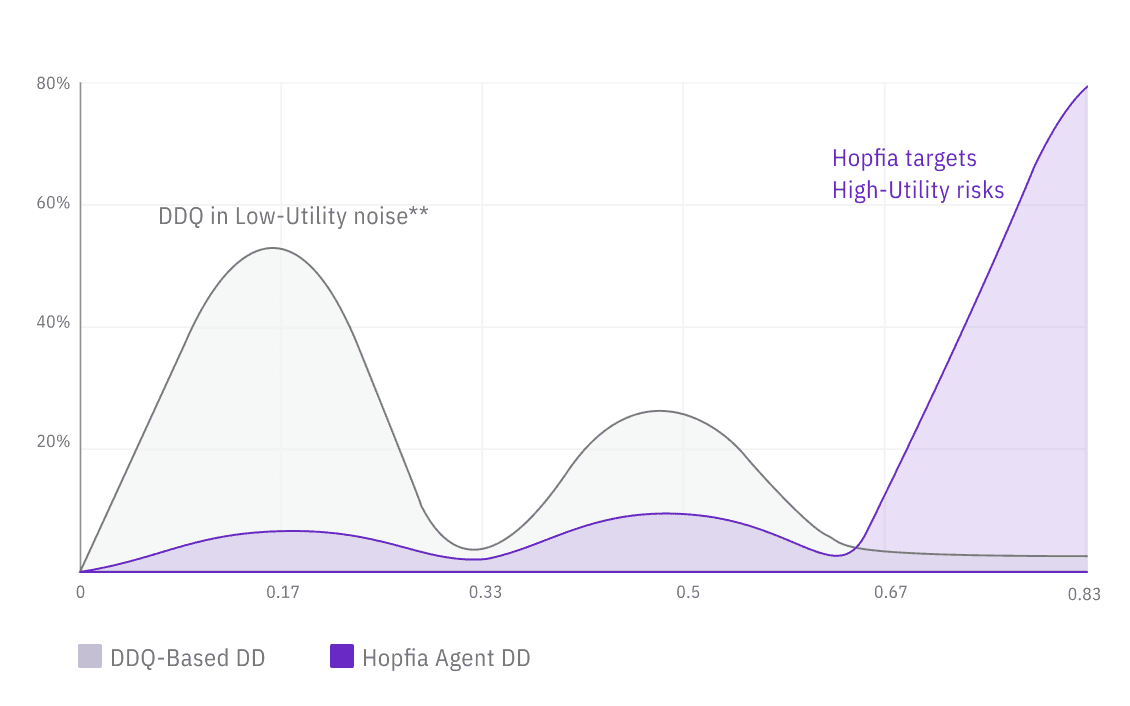
When supporting evidence was reduced, the proportion of findings that experienced a decline in evaluation was:
16.3% for the DDQ-based approach
5.9% for the autonomous agent approach
representing a relative difference of approximately 276%.
This suggests that findings produced by the autonomous agent approach are, on average, more robustly supported by underlying evidence, whereas the DDQ-based approach exhibits a higher sensitivity to the removal of supporting context.
In practical terms, this indicates that:
DDQ-based outputs are more likely to rely on surface-level coherence, and their perceived validity is more prone to degradation when explicit evidence is removed.
By contrast, autonomous agent–generated findings tend to maintain their evaluative strength even under reduced evidence conditions, implying a stronger alignment between conclusion and supporting data.
Reframing the Evaluation Metric: Information Utility
This benchmark concludes that due diligence outputs are more effectively evaluated under a different framework.
Information Utility — The extent to which each diligence finding impacts investment decisions and contributes to decision-making
This metric moves beyond simple measures such as information volume or checklist completion, and instead evaluates:
whether a risk is clearly defined
how that risk connects to deal-level impact and investment judgment
whether the output can be directly utilized without additional interpretation
Accordingly, Utility can be understood as a measure of both:
deal-level impact, and
the ability of information to be transformed into actionable decisions
Results: Output Volume vs. Decision Utility
The results show a clear divergence between the two approaches.
This indicates that:
The DDQ approach generates a higher volume of findings
The autonomous agent approach produces findings with significantly higher decision relevance
Output quantity and decision utility do not scale together.
Interpretation
The benchmark suggests that the key differentiator in AI-driven due diligence is not the volume of information processed, but how that information is structured.
DDQ-based systems are effective for coverage and completeness
Autonomous agents are more effective in constructing decision-ready insights
In this evaluation:
Autonomous agents demonstrate a higher density of decision-relevant outputs
Conclusion
AI-driven due diligence should not be evaluated based on response volume or checklist completion alone.
The relevant benchmark is how effectively outputs contribute to investment decisions.
This benchmark shows that autonomous AI agents operate more effectively in this dimension, transforming raw information into structured, decision-ready insights.
Summary
The goal of due diligence is not to collect information, but to structure it into decisions.